The Statistics window can most conveniently be viewed by pressing F5 (Window : Layout : Warrior layout).
The picture below shows an exemplary Statistics window. The description of individual fields is presented below the picture. Click the picture now to open it in a separate window for easy comparison of fields and their descriptions:
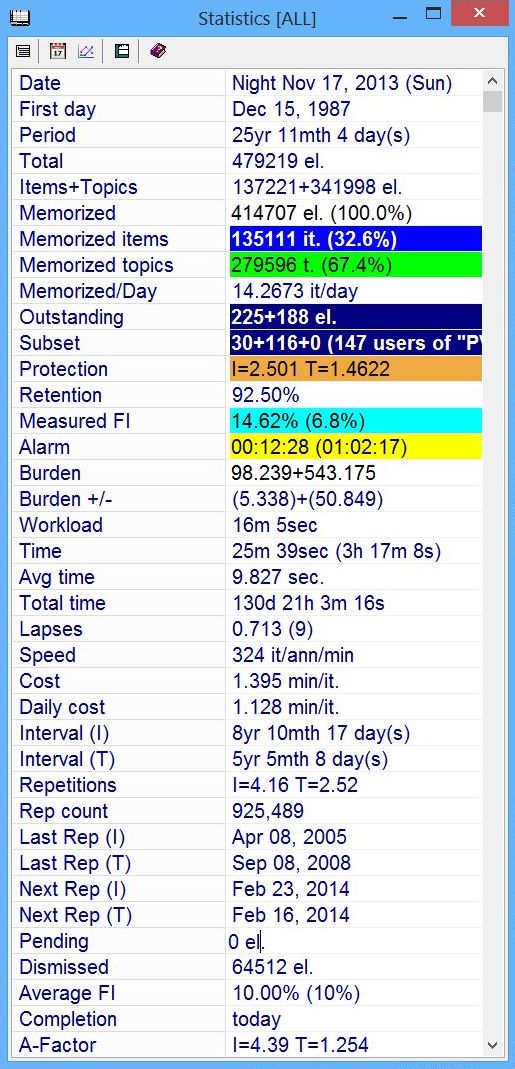
The caption of the statistics window displays the name of the collection in square brackets. The presented collection is named All.
Learning parameters displayed in the statistics window:
- Date - current date and the day of the week. If this value is preceded with Night, it means that the new calendar day has already started but the old repetition day will not start until the time defined in Tools : Options : Learning : Midnight shift (hours). In the example above, the picture snapshot was taken after midnight on Nov 17, 2013 (Sunday)
- First day - date on which the learning process began (i.e. the day on which the first element was memorized). The exemplary collection presented in the picture has been in use since December 15, 1987 (i.e. the birth date of SuperMemo for DOS)
- Period - number of days in the learning process (i.e. number of days between Date and First day).
Period=Date-First day.
The presented collection has been in use for 25 years, 11 months and 4 days) - Total - the number of items, topics and tasks in the collection. Two relationships hold true:
- Memorized+Pending+Dismissed=Total
- Topics+Items=Total (tasks are counted with the Topics statistic)
Deleted elements do not contribute to the total count of elements in the system. In the picture, the presented collection is made of 479,219 elements (largest collections reported by users reached beyond a half million elements)
- Items+Topics - the number of items and the number of topics (and tasks) in the collection.
Items+Topics=Total.
In the example, the collection includes 137,221 items and 341,998 topics (and tasks) - Memorized - total number of elements introduced into the learning process with options such as Learn or Remember. If an item takes part in repetitions it is a memorized item. It does not mean it is a remembered item. A proportion of memorized items is always forgotten. The presented collection has 414,707 elements in the learning process and these elements make up 100.0% of all elements destined to enter the learning process, i.e. Memorized/(Memorized+Pending)=100.0. This indicates that Pending=0 (see below)
- Memorized items - the number of memorized items in the collection and the proportion of memorized items among memorized elements. In the example above, 135,111 items take part in repetitions. These items make 32.6% of all elements taking part in the learning process (the remaining 67.4% of elements are memorized topics or memorized tasks). The Retention field (below) indicates that 92.5% of these items should be remembered at any given time
- Memorized topics - the number of memorized topics and the proportion of memorized topics among all memorized elements. In a well-balanced incremental reading process, topics should make a minority of elements served for review. If the proportion of topics increases, the retention drops, and the learning process may gradually start to resemble traditional learning where ineffective passive review predominates. You can store as many topics in your collection as you wish as long as you make sure that you limit their review by setting appropriate repetition sorting criteria ( Learn : Sorting : Sorting criteria). In the picture, 279,596 topics make 67.4% of the material taking part in the learning process
- Memorized/Day - number of items memorized per day: (Memorized items)/Day. In the example, the average of 14.2673 items have been memorized daily in the presented collection over the previous almost 26 years. This is typical of an average student as long as regular reviews are executed on a daily basis
- Outstanding - number of outstanding items, outstanding topics and final drill items scheduled for repetition on this given day. The first number (before the plus sign) indicates the number of items scheduled for this given day and not yet processed. The second number (after the plus sign) indicates the number of topics scheduled for review for this day. The third number (after the second plus sign), if present, indicates the number of items that have already been repeated today but scored less than Good (4). Those are the items that make up the final drill queue. The final drill queue is built only if Skip final drill is unchecked in Tools : Options : Learning. In the presented collection, there are still 225 items scheduled for repetition on Nov 17, 2013. There are also 188 topics scheduled for review on that day as part of the incremental reading process. There are no elements in the final drill queue (the third component of the Outstanding parameter is missing)
- Subset - number of elements scheduled for subset review (e.g. elements in branch repetitions in Contents : Learn, elements in browser subset repetitions in the browser's Learn, elements in the random test queue in Tools : Random test, etc.). The display may have a form of <items to do>+<topics to do>+<pending to do>+(<subset description>) in subset review, or <elements unprocessed>/<all elements in the test> in random tests. Here 147 elements remain in subset review. 30 items, 116 topics and 0 pending elements. The subset on which Learn is being executed contains 147 elements and has been generated by searching for the keyword "PVN". In other words, there are still 30 items to repeat and 116 topics to review that refer to the learning subject "PVN" in the whole body of 147 elements related to the paraventricular nucleus. In incremental reading, subset repetitions are most often executed in the contents window or in the browser with Learning : Learn (Ctrl+L) or with Learning : Review all (Shift+Ctrl+L). In the later case, not only outstanding elements are reviewed. The remaining elements are subject to mid-interval review as well
- Protection - Today's degree of processing top priority material. Important: As the statistic is taken from the top of the queue of outstanding items or topics (not the top of outstanding queue, which is randomized mix of the two), if you change the priority of the top item, you will see a false value in Statistics until you review that item of changed priority (this behavior is by design to prevent the need to scan the entire queue at each update to statistics). In the example, only 2.5% of top priority items, and 1.46% of top priority topics have been processed. 2.5% protection does not mean going through 2.5% of the outstanding items queue. It means that the highest priority of unprocessed items in the queue is 2.5%
- Retention - estimated average knowledge retention in the collection. Retention for high-priority items should be higher than the one listed. Retention for low-priority items may be much lower driving the average down. To judge upon the retention of top-priority material, see Tools : Statistics : Analysis : Graphs : Forgetting index vs. Priority. In the example, 92.5% of the material should be recalled in a random test on all elements in the collection at any time. You can test your retention using random tests and see if SuperMemo's estimates are accurate. This statistic may be overly optimistic if you have recently abused rescheduling tools such as Postpone or Mercy.
- Measured FI - the value of the measured forgetting index as recorded during repetitions. The measured forgetting index is the proportion of items not remembered during repetitions. The number in the parentheses indicates Measured FI for the day. In collections with heavy item overload, measured forgetting index may be much lower than the overall forgetting index for the entire collection due to the fact that repetitions include primarily high-priority material. It can also be lower than the requested forgetting index when transitioning from more randomized to more prioritized sorting (as determined by sorting criteria) or when knowledge formulation and mnemonic skills improve before this fact can be reflected in the forgetting curve. It is also not uncommon to have Measured FI higher than Average FI. This is due to three factors:
- every user will experience delays in repetitions from time to time (e.g. as a result of using Postpone),
- low-priority material in the overloaded incremental reading process is scheduled in intervals longer than optimum intervals, and
- SuperMemo imposes some constraints on the length of intervals that, in some cases, make it schedule repetitions later than it would be implied by the forgetting index. The constraints in computing intervals, for example, prevent the new interval from being shorter than the old interval (assuming the item has not been forgotten). For low values of the forgetting index and items with a low A-Factor, the new optimum interval might often be shorter than the old one! Measured FI can be reset with Tools : Statistics : Reset parameters : Forgetting index record.
- In the presented example, an average of 14.62% of item repetitions end with a grade less than Pass (3) (since the measured forgetting index record has last been reset). On Nov 17, 2013, 6.8% of repetitions ended in failure thus far (i.e. with a grade less than Pass)..
- Alarm - time left till the next alarm and the hour at which the alarm will ring off (to learn more about alarms see: Plan). This field is editable. To change the alarm setting, click the field and type in the new time in minutes (e.g. 21.5 will set the alarm to sound in 21 minutes and 30 seconds). To end editing, press Enter. In the example, the alarm will sound off in 12 minutes and 28 seconds at 01:02:17
- Burden - estimation of the average number of items and topics repeated per day. This value is equal to the sum of all interval reciprocals (i.e. 1/interval). The interpretation of this number is as follows: every item with interval of 100 days is on average repeated 1/100 times per day. Thus the sum of interval reciprocals is a good indicator of the total repetition workload in the collection. The presented collection requires 98 item repetitions per day and 543 topic reviews per day. In incremental reading, it is not unusual to have many more elements in the process than one can handle. Auto-postpone can be used to unload the excess of topics as well as to reduce the load of low-priority items. Postpone skews the Burden statistic. Topics often crowd at lower intervals and are regularly reshuffled with Postpone or Auto-postpone
- Burden +/- - the change of the Burden parameter above on a given day. Here, on Nov 17, 2013, the average number of expected daily repetitions was slightly increased (i.e. by 5 items). The topic load was also increased (i.e. by almost 51 topics). Exemplary interpretation of a burden change: Let's say the burden dropped by 39 (burden change of -39). To reduce the burden by 39, one would need to review 78 elements with an interval increase from 1 to 2 days (78*0.5=39). However, one could equally well execute Postpone on 2344 elements with interval increase from 10 to 12 days (2344*(1/10-1/12)=39)
- Workload - estimation of the average daily time used for responding to questions in a given collection.
Workload = (Item Burden)*Avg time
In the presented collection, 98 item repetitions per day taking 9.827 seconds each result in a daily repetition time estimated at 16 minutes and 5 seconds. A real learning time may be twice longer due to grading, editing, reviewing the collection and various interruptions. In incremental reading, the learning time will increase further due to topic review that is not taken into account in the Workload parameter. The real learning time may also be cut if Postpone is used often - Time - total question response time on a given day and the total session time (in parentheses). Here the total time needed to respond to questions on Nov 17, 2013 was 25 minutes and 39 seconds. On the same day, SuperMemo has been running for 3 hours, 17 minutes and 8 seconds (this value will increase even if you simply keep SuperMemo running)
- Avg time - average response time in seconds. This is the time that elapses between displaying the question (or equivalent) and choosing Show answer (or equivalent). The timer does not stop if you start editing the question before pressing Show answer In the presented collection, the average time to answer a single question is around 9.827 seconds. If this number grows beyond 15-20 seconds, you may need to analyze your learning material if it is not overly difficult or badly structured
- Total time - total time taken by responding to questions in the collection. This time cannot be accurately measured for collections created with SuperMemo 98 or earlier (the measurements were made possible only in SuperMemo 99). If you upgrade older collections, this number will roughly be guessed for you. SuperMemo will derive this time from the total number of items, average number of repetitions, average number of lapses, and the average repetition time. In the presented example, answering questions during repetitions took the total of almost 131 days in almost 26 years of learning
- Lapses - average number of times individual items have been forgotten in the collection (only memorized elements are averaged). The number in parentheses shows the number of lapses on a given day. Here an average element has been forgotten 0.713 times. On Nov 17, 2013, 9 items have thus far been graded less than Pass (3)
- Speed - the average knowledge acquisition rate, i.e. the number of items memorized per year per minute of daily work. Initially this value may be as high as 100,000 items/year/minute (esp. if you enthusiastically start working with the program before truly measuring its limitations; or to be precise: the limitations of human memory); however, it should later stabilize between 40 and 400 items/year/minute.
Speed=(Memorized items/Day)/Workload*365
In the presented collection, every minute of work per day resulted in 324 new items memorized each year. As this value is derived from Burden, it may be highly underestimated if you use Postpone a lot (e.g. in incremental reading) - Cost - the cost in time of memorizing a single item, i.e. total learning time divided by the number of memorized items.
Cost = Total time/Memorized
In the presented example, the total repetition time per single item is 1.395 minutes. In other words, each item has contributed around 1.4 minutes to the total of non-stop almost 131 days of repetitions. The cost of editing, collection restructuring, incremental reading, etc. is not included in the Cost parameter - Daily cost - daily repetition time per each newly memorized item.
Daily cost = Workload/(Memorized items/Day)
In the presented collection, each of the 14 newly memorized items per day contributes about 1.1 minutes of repetitions (precisely 1.128 minute) to the total workload of over 16 minutes per day. As this value is derived from Burden, it may be highly overestimated if you use Postpone a lot (e.g. in incremental reading) - Interval (I) - average interval among memorized items in the collection. Here an average memorized item has reached the inter-repetition interval of 8 years, 10 months and 17 days
- Interval (T) - average interval among memorized topics in the collection. Here an average memorized topic has reached the inter-repetition interval of 5 years, 5 months and 8 days
- Repetitions - average number of repetitions/reviews per memorized item (I) and topic (T) in the collection. Here an average item has been repeated 4.16 times while an average topic has been reviewed 2.52 times
- Rep count - the total count of item repetitions made in the collection. In the presented collection, 925 thousands of item repetitions have been made. This is about 7 repetitions per memorized item. That includes repetitions of items that have been reset, forgotten, dismissed, deleted, etc.
- Last Rep (I) - average date of the last repetition among memorized items in the collection. Here the average date of the last repetition is April 8, 2005
- Last Rep (T) - average date of the last review among memorized topics in the collection. Here the average date of the last review is September 8, 2008
- Next Rep (I) - average date of the next repetition among memorized items in the collection.
Next Rep = Last Rep + Interval
Here the average date of the next repetition is February 23, 2014 or 3,243 days after April 8, 2005 - Next Rep (T) - average date of the next review among memorized topics in the collection. Here the average date of the next review is February 16, 2014
- Pending - the number of elements (topics or items) that have not yet been introduced into the learning process and await memorization (with operations such as Learn, Remember, Schedule, etc). All pending elements are kept in the so-called pending queue that determines the sequence of learning new elements. Dismissed elements are not kept in the pending queue. In the example, the collection contains no pending elements. With incremental reading, the role of the pending queue in SuperMemo is diminishing
- Dismissed - the number of elements (topics, items or tasks) that have been excluded from the learning process and are kept only as reference material, folders in the knowledge tree, or tasklist elements. Dismissed items are neither pending nor memorized. All tasks are dismissed by default, i.e. they usually do not take part in repetitions. In the example, over 64,000 elements have been dismissed
- Average FI - the average requested forgetting index in the entire collection (the number in parentheses is the default forgetting index). If the forgetting index of individual elements is not changed manually, Average FI is equal to the default forgetting index as set in Tools : Options : Learning : Forgetting index. The default forgetting index is the requested forgetting index given to all categories and, as a result, to all new items added to the collection. Forgetting index, in general, is the proportion of items that are not remembered during repetitions. The lower the value of the forgetting index the better the recall of the element, but the more repetitions will be needed to keep it in memory. Optimum value of the forgetting index falls into the range from 7% to 13%. Too low a forgetting index makes learning too tiresome due to a prohibitively large number of repetitions. All elements can have their desired forgetting index set individually. The easiest way to change the forgetting index of a large number of elements is to use Forgetting index option among subset operations. In the presented example, the average forgetting index is 10.00% while the default forgetting index is 10%. See: Using forgetting index
- Completion - the expected date on which all elements from the pending queue will be memorized assuming the present rate of learning new items. This parameter is particularly useful if you are memorizing large ready-made collections such as Advanced English. For Pending=0, the value of this field is today.
Completion=Date+(Pending/(Memorized items/Day)) - A-Factor - average value of A-Factor among memorized items (I) and topics (T) in the collection. For items, A-Factor is a measure of difficulty. The higher the A-Factor, the easier the item. For topics, A-Factor is the number by which the current interval should be multiplied to get the value of the next interval. In the presented collection, the average A-Factor for items is 4.39. This indicates that the collection is rather well-structured and the material is thus relatively easy to remember. The average A-Factor for topics is 1.254
Comments:
- Items are added to the final drill not only during standard repetitions when you grade an element below Good (4). Operations such as Remember (Ctrl+M), Cloze (Alt+Z), and Add to drill (Shift+Ctrl+D) will also add to the final drill queue. The final drill queue is created automatically only if you uncheck Tools : Options : Learning : Skip final drill
- Some fields of the Statistics window can be edited. For example: Alarm, Total time, Rep count, etc. To edit and entry, click it, type the new value and press Enter. If the entry cannot be modified SuperMemo will warn you (e.g. "Retention entry cannot be modified").
- See Survey 1994 and Survey 1999 for some interesting notes about the speed of learning reached with SuperMemo